prompt
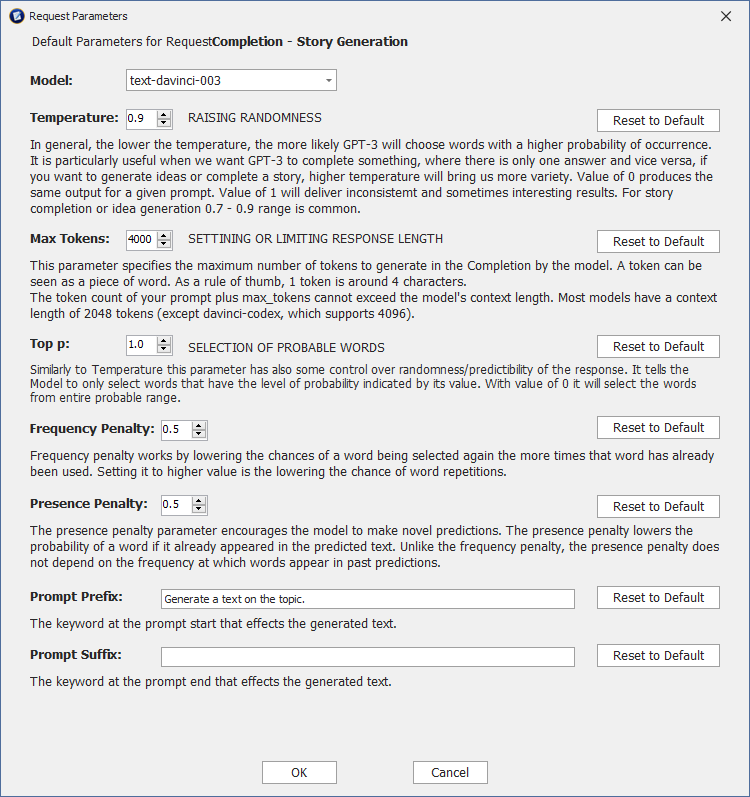
This is the starting text that you provide to the model, which it will use to generate additional text. For example, you might provide a sentence like "I went for a walk in the park and saw a" and the model will generate the next few words to complete the sentence. The model can generate much more complex and detailed text even for a short textual prompt like "Travelling San Diego".
max_tokens
This parameter determines the length of the generated text. It specifies the maximum number of words or word-like units (known as "tokens") that the model should generate in response to the prompt. The maximum number of tokens for davinci model is 4,000, while for the rest of the models is 2,000.
num_return_sequences
This parameter allows you to generate multiple variations of the text completion for a single prompt. It specifies the number of different text completions the model should generate. In Word Express this parameter is not configurable and by default is has value 1.
temperature
This parameter controls how creative or random the generated text will be. A lower temperature (such as 0.1) will result in more predictable and straightforward text, while a higher temperature (such as 0.9) will result in more diverse and imaginative text. This parameter can be set to a value in the range of 0 to 1.
top_p
This is a decimal value between 0 and 1 that specifies the proportion of the overall range of possible completions to consider when generating text. For example, if you set top_p to 0.9, the model will consider the most likely 90% of possible completions when generating text.
presence_penalty
This is a positive decimal value in the range of 0 to 1 that encourages the model to generate unique and diverse text. The presence penalty imposes a score penalty on any tokens that have a low probability of appearing according to the model's predictions.
repetition_penalty
This is a positive decimal value in the range of 0 to 1 that discourages the model from repeating text from the prompt. The repetition penalty imposes a score penalty on any tokens that are repeated from the starting text.
best_of
This parameter is used to select the best response from multiple text completions generated for a single prompt. It specifies the number of top-scoring text completions to consider when making the final selection. This parameter is not configurable in Word Express to prevent excessive token consumption and therefore, reducing the cost. This parameter is not configurable in Word Express.
By adjusting these parameters, you can customize the generated text to suit your specific needs and preferences. For example, you might use a higher temperature value to generate more imaginative and creative text for a fiction-writing task, while you might use a lower temperature value to generate more straightforward and accurate text for a news article.
While changing the parameter values you can always return to the application default value by clicking on Reset to Default button for each modified value. The default values may change from time to time as our team enhances the values. These team might be updated through Update button capability on the Word Express tab ribbon as newer versions of the add- in become available.