GPT4Audio Overview
Translating Audio and Video Files
GPT4Audio is a powerful tool for transcribing audio and video files in a variety of formats, including:
- MP3
- MP4
- MPEG
- MPGA
- M4A
- WAV
- WEBM
Whisper technology automatically identifies the language used in your audio or video files. However, you can also choose to specify the language yourself by selecting it from the dropdown menu on the Application Ribbon.
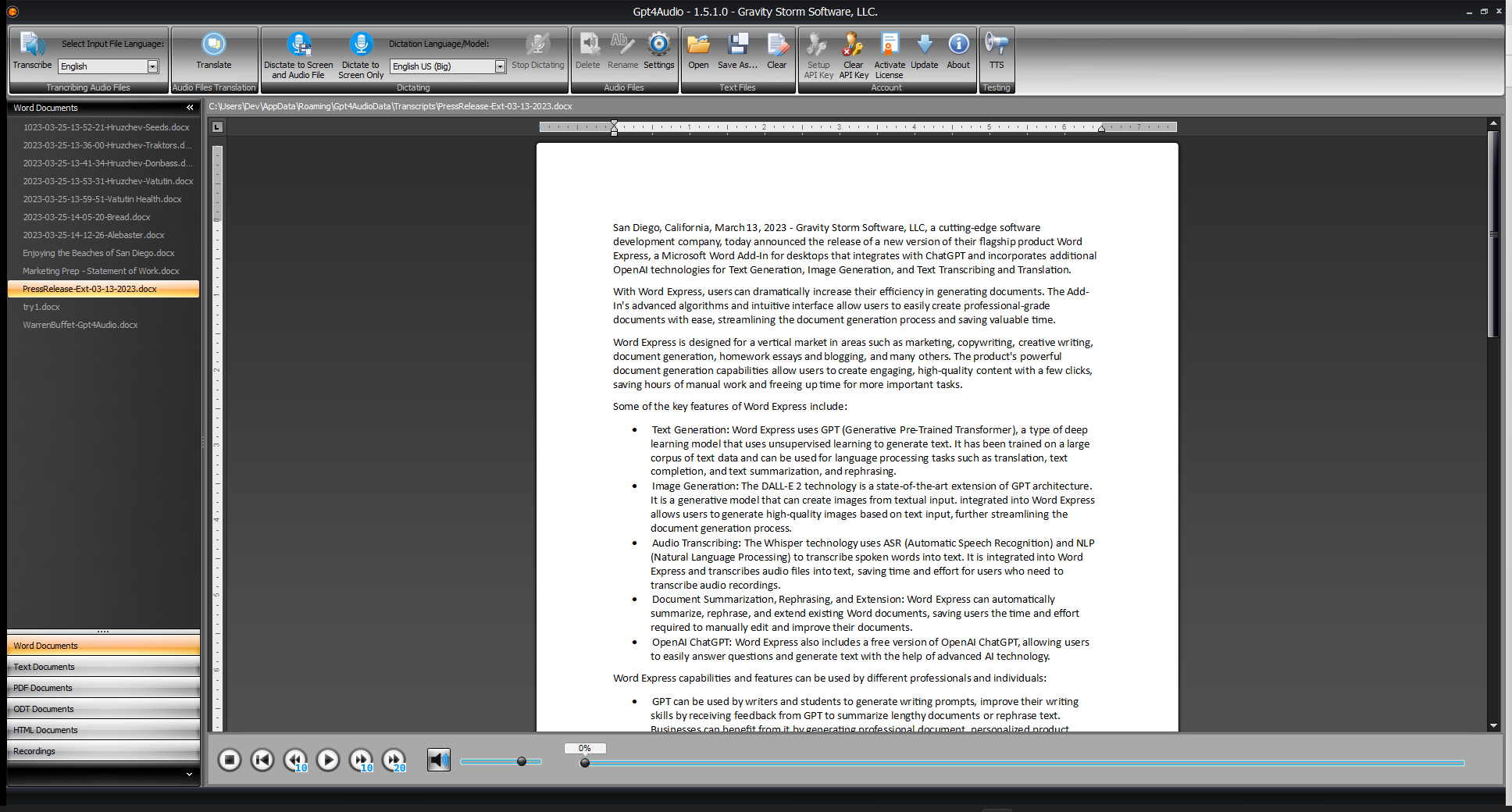
To start transcribing, simply click the “Transcribe” button on the Application Ribbon and choose your file. GPT4Audio will quickly and accurately generate a transcription, displaying the text on your screen.
Once transcribed, you can save the text in several popular file formats:
- DOCX (Microsoft Word Document)
- PDF (Portable Document Format)
- TXT (Plain Text)
- ODT (Open Document Text)
- HTML (Web Pages)
Your saved transcriptions will appear in their respective file groups in the Navigation Bar on the left side of the application. To open and review a saved transcription, select the file and click the “Open” button on the Application Ribbon.
Translating Audio and Video Files
GPT4Office is a versatile tool for translating audio and video files in a range of formats, including:
- MP3
- MP4
- MPEG
- MPGA
- M4A
- WAV
- WEBM
Our software efficiently translates audio and video files from various languages into English. GPT4Office supports translations from 57 different languages, offering a wide range of options for users.
Whisper is an advanced, general-purpose speech recognition model that is trained on a vast dataset of diverse audio sources. As a multitasking model, Whisper is capable of performing multilingual speech recognition, speech translation, and language identification tasks.
Dictation
GPT4Audio offers integrated dictation models of varying sizes for different languages. While the supported languages and models differ from OpenAI’s Whisper and may not cover as many languages, GPT4Audio provides a unique dictation experience for users.
It’s important to note that only a select number of ‘Small’ models are included with the GPT4Audio installer due to the large size of ‘Large’ models, which often exceed 1GB.
The default model is the English Lightweight Small Model (40MB), which is included with the GPT4Audio installer. When users select a model from the “Dictation Language Model” combo box on the Application Ribbon, the application checks whether the chosen model is available on the user’s machine. If not, the application prompts the user to download the selected model.
Upon user acceptance, the model is downloaded, unzipped, and ready for use. The downloading and unzipping process may take some time, depending on the user’s internet connection speed.
Users can then click on either of the two buttons on the Application Ribbon (“Dictate to Screen and Audio File” or “Dictate to Screen Only”) and begin dictating into the microphone.
To stop dictation, users can click the “Stop Dictating” button on the Application Ribbon. The recording then stops, the recorded file is saved, and it appears in the Recordings Group in the Navigation Bar on the left.
Dictation can be saved in WAV or MP3 formats. Users can choose the recording format before starting the recording by clicking the Settings button on the Application Ribbon.
Like other files in the Navigation Bar, recorded files can be renamed or deleted.
GPT4Audio also includes playback functionality. Users can select a recorded file in the Recordings Group and click the Play button on the embedded player. Playback can be further controlled with Pause, Continue, Fast Forward (10 or 20 seconds), Rewind (10 seconds), or Full Rewind options.
Supported Languages and Language Models
GPT4Audio supports numerous languages for transcription and translation. While translation is limited to English, transcription is available in the audio file’s original language.
The supported languages for transcription and translation include:
Afrikaans, Arabic, Armenian, Azerbaijani, Belarusian, Bosnian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Finnish, French, Galician, German, Greek, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Kannada, Kazakh, Korean, Latvian, Lithuanian, Macedonian, Malay, Marathi, Maori, Nepali, Norwegian, Persian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovenian, Spanish, Swahili, Swedish, Tagalog, Tamil, Thai, Turkish, Ukrainian, Urdu, Vietnamese, and Welsh.
For dictation, the supported languages and models are:
- English Lightweight (Small)
- English US Generic (Large)
- English US (Large)
- English Dictation (Large)
- English Generic Indian (Large)
- English Lightweight Indian (Small)
- French Lightweight (Small)
- French (Large)
- German (Large)
- German (Small)
- Spanish (Small)
- Spanish (Large)
- Dutch (Small)
- Dutch Dynamic Graph (Small)
- Swedish (Medium)
- Korean Lightweight (Small)
User can select the Language Model from the Dictation Language/Model Combo Box on the Application Ribbon prior to dictation start .
Audio File Limitation
By default, the Whisper API supports files smaller than 25 MB. For larger audio files, consider breaking them into chunks of 25 MB or less or using a compressed audio format. To ensure optimal performance, avoid splitting audio files mid-sentence, as it may result in loss of context.
Although the underlying model was trained on 98 languages, only languages with a word error rate (WER) below 50% are listed, as WER is an industry-standard benchmark for speech-to-text model accuracy. The model can return results for unlisted languages, but the quality may be low.
PURCHASING
GPT4AUDIO-STD-S-A
Standard Annual Subscription
$8/mo. Billed Annualy
You pay $96 today.
Single User
Includes Updates for 1 year.
Audio/Video File Transcribing
Audio/Video File Translating to English
Dictation to Microphone
Audio Playback
GPT4AUDIO-STD-S-M
Standard Monthly Subscription
$10/mo. Billed Monthly
You pay $10 today.
Single User
Includes Updates for 1 year.
Audio/Video File Transcribing
Audio/Video File Translating to English
Dictation to Microphone
Audio Playback
GPT4AUDIO-STD-P
Standard Monthly Subscription
$75 One Time Payment
You pay $75 today.
Single User
Does not iclude Updates.
Audio/Video File Transcribing
Audio/Video File Translating to English
Dictation to Microphone
Audio Playback